This blog gives an introduction to, and a snapshot update, of our micromodel technology as well as our future roadmap. The technology is designed to address challenges in applying Artificial Intelligence into real-world, dynamic operational contexts to support the capture and delivery of effective decision intelligence.
What are micromodels?
The concept is pretty simple. We look at a large, complex problem and break it up into smaller, more specific chunks, deploying targeted AI models to specific parts of the problem. We then network multiple models together with other data and models, creating a dynamic network of micromodels.
The technology addresses a few key challenges in the deployment of AI in complex, dynamic and multistakeholder environments.
- Maintaining data segmentation: Many environments today are multistakeholder, comprising multiple independent and separate organisations, working together to deliver a process or function. The data required to deliver effective intelligence often lives across these ecosystems of stakeholders. Clearly, that presents a challenge with regard to data sharing, privacy, and security. The idea of putting data into a ‘black box’ (a term often used to describe large deep-learning models) alongside potentially competitive organisations is a non-starter. Micromodels enable data to be input into a smaller model with the derived outputs networked with other outputs from other models. This ensures data segmentation and granular permission-based controls can be maintained.
- Understandable/explainable outputs: In the operational context, being able to understand how a prediction has come to be is important. Both in terms of trust and being able to inform others to drive action. After all, an insight is only impactful if it is followed by action. Having a network of models that are visible supports understanding meaning operators can trust the outputs.
- Dynamic intelligence: In many cases, operational environments are subject to happenings that have correlation (meaning they can be predicted) but are also filled with events that appear random (or at least, more random). We call these ‘black swan’ or outliner events. It’s the human aspect that often drives this unpredictability. One of the foundational concepts behind micromodels is the ability to combine stochastic models with deterministic models. Put another way, being able to combine things that have mathematical correlations with others that are random but have an impact.
- Model/data fit: Another benefit of breaking things down is the increased resolution in areas. This makes it much easier to achieve a good model data fit which ultimately improves the performance of the models within the overall network.
- Being able to deploy iterative: In most cases, getting data is the hardest bit. Gathering data from different stakeholders or having dependencies on data sources that require new systems to be implemented and so on can slow things down. However, the micromodel concept allows for new models and new data to be introduced over time. Instead of waiting for everything, models can be deployed to specific parts of the problem iteratively, growing the network over time. This reduces dependencies and gets to value more quickly, which then encourages more data sharing when others see the network taking shape and delivering value.
Initial use case.
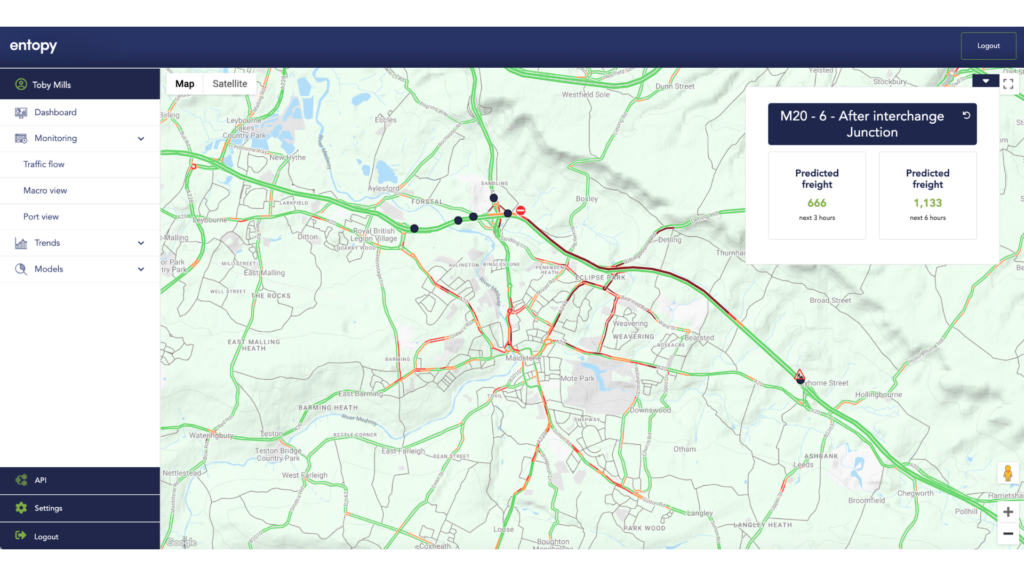
The initial iteration of our micromodel technology has naturally been use-case-led, delivering dynamic intelligence of future traffic flows to a major UK port, which we will elaborate more specifically on in a later blog and case study. But at a high-level, it required micromodels to be deployed as part of a Digital Twin across the strategic road network of the port.
This required us to develop AI models capable of predicting traffic flows in specific areas of road, and leverage data from third-party models such as weather forecasts and network models together with real-time event-based data such as traffic accidents and scheduled road maintenance, with an overarching orchestration model.
This was a perfect initial use case for the technology as road networks naturally have many variables – they are dynamic. There are regular occurrences of ‘black swan’ events, and many stakeholders involved, have a need for iterative deployment (more so in the extension of an initial twin over time) and within the context of the use case, supporting operators to make more data-driven decisions regarding traffic management protocols, a high need for explainable outputs to build confidence in the intelligence and ultimate, drive action.
And, although use-case-led, the initial iteration of Entopy’s micromodel technology has wide applicability. By breaking the overall problem into smaller, more specific chunks, you create ‘atomic models for atomic problems’. For example, the micromodels deployed for this use case can easily support use cases for other infrastructures such as airports, councils, shopping centres, stadiums etc. where predictive intelligence regarding traffic movement is needed.
Over the past months, we have been able to validate the technology, prove key aspects, achieve many key technical milestones, automate key aspects of the technology to ensure high repeatability and transferability to other use cases and flesh out our future roadmap.
Model performance.
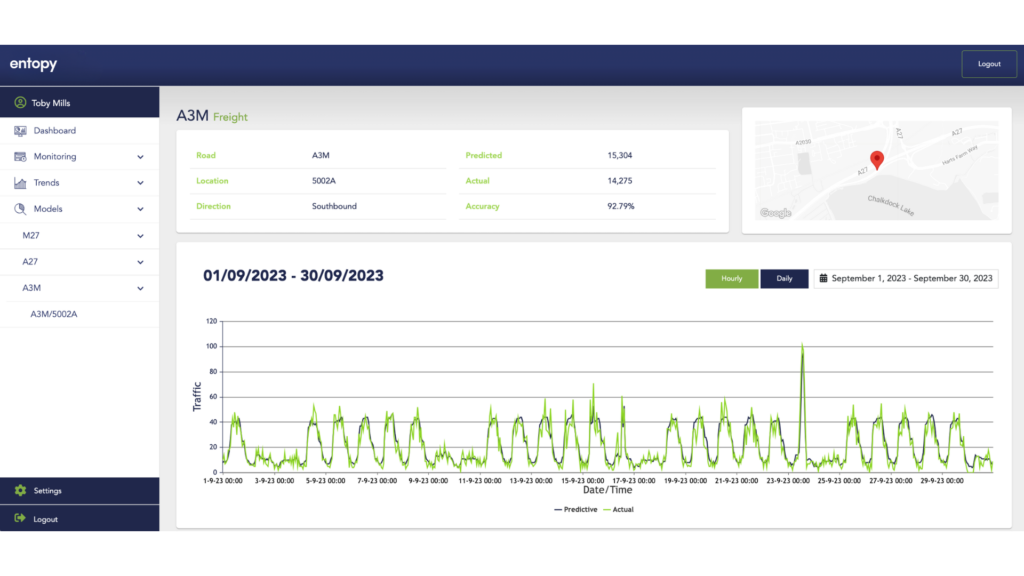
The performance of AI models within the use case has been exceptional. By breaking the problem into smaller chunks, increasing the resolution of specific parts of the problem. We have been able to get a very good model/data fit very quickly.
The models are purposely small, with the initial traffic flow model comprising only 26 features. Multiple instances of these models are deployed, operating independently, and networked together. Not only does this support dynamic intelligence but also acts as a good check and balance across the network.
We have now deployed many models across the UK with an average accuracy of >85%. Below is a screenshot of a model recently deployed showing the model capturing a significant and outlining spike in traffic flow. The blue line is the prediction, the green line is what happened.